Principes du web Architecture
Le web repose sur une architecture client/serveur :
- le client : c’est un ordinateur avec :
- un client web : un logiciel qui effectue une requête HTTP et qui effectue le rendu de la page. Le plus souvent un navigateur (Chrome, Firefox, Edge/Internet Explorer, Safari, Opera, Samsung Browser, Brave, Vivaldi, Lynx, etc.) mais un simple terminal peut suffire.
- le serveur : c’est un ordinateur avec :
- un serveur web : un logiciel qui reçoit les requêtes et retourne le document demandé. (Apache, nginx, Node.js, TomCat, etc.)
- un accès au système de fichiers pour héberger des documents
- un environnement d’éxécution de code
- un système de base de données
- etc.

Dans l’exemple ci-dessus, le navigateur (client web) initie une requête vers le site http://www.example.com. Le serveur web qui héberge ce site réponds alors la ressource demandée (un seul fichier à la fois)
Note
Un serveur web peut également jouer le rôle de client web si une requête est effectuée vers un autre serveur.
Le Web est basé sur Internet, et notamment sur le protocole TCP/IP et DNS.
Les 3 inventions à la base du Web sont :
- Les URLs
- Le protocole HTTP (une surcouche à TCP)
- Le langage HTML
DNS#
C’est le Domain Name System. Ce service permet de traduire une adresse web (un nom de domaine) en adresse IP, utilisable sur le réseau. Cela permet donc d’utiliser des URLs de la forme http://google.fr au lieu de http://75.23.56.154.
Une web-BD qui explique tout ça en détail
Dans notre exemple précédent
# DNS récupère adresse IP (v6)
example.com => 2606:2800:220:1:248:1893:25c8:1946
URL (Uniform Resource Locator)#
Ce sont les ressources du WWW. Une URL identifie précisément une (et une seule) ressource sur le réseau (les pages web, les images, les polices, etc.)
Une URL se décompose de la sorte :
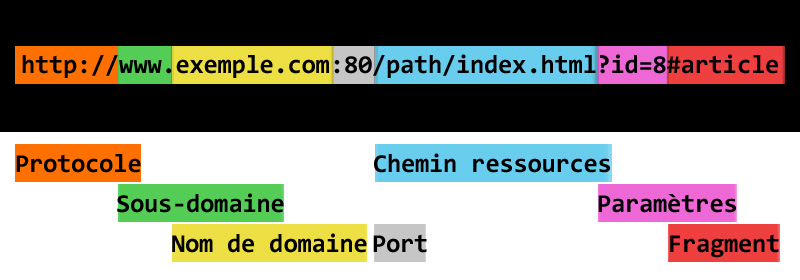
http://Protocole HTTP ou HTTPSwwwSous-domaineexemple.comNom de domaine (+extension):80Port facultatif (défaut: HTTP: 80, HTTPS: 443)
Suivi de :
chemin/page.htmlChemin de la ressource (pas forcément de correspondance exacte)?id=8&name=nomParamètres de la requête (query string)#ancreFragment (lien dans la page)
Protocole HTTP (HyperText Transfer Protocol)#
C’est un protocole de communication client-serveur. Ce protocole repose sur différents types de méthodes :
GETpour demander une ressourcePOSTpour envoyer des données (depuis un formulaire par exemple)- et pleins d’autres:
PUT,DELETE,HEAD, etc
La variante sécurisée est HTTPS.
Requêtes#
Pour chaque requête, du client vers le serveur, mais également du serveur vers le client (réponse), des métadonnées sont associées.
Requête HTTP
GET /page.html HTTP/1.0
Host: example.com
Réponse HTTP
HTTP/1.0 200 OK
Date: Sat, 11 Oct 2014 13:18:48 GMT
Server: Apache/2.2.26 (Unix)
Content-Type: text/html
Content-Length: 14
<p>Content</p>
Dans notre cas, on pourra alors être plus précis pour la communication client/serveur :

Le client initie une requête de type GET vers l’URL / (slash = racine du site) sur l’host example.com. Le serveur associé renvoie le contenu du fichier et son type (text/html), en précisant que tout s’est bien déroulé (code 200 OK).
Voici d’autres exemples de requêtes possibles :
Requête GET
GET /dossier/page.html HTTP/1.0
Host: localhost
Requêtes avec passage de paramètres
GET /dossier/page.php?id=42 HTTP/1.0
Host: localhost
POST /dossier/page.php HTTP/1.0
Host: localhost
Content-Type: application/x-www-form-urlencoded
Content-Length: 5
id=42
Codes HTTP#
Chaque requête HTTP renvoit un code de retour :
200: OK, la requête a fonctionnée301,302: une redirection a eu lieu sur le serveur304: la ressource est renvoyée du cache (même si elle a pu être modifiée entre-temps)403: la ressource existe, mais l’accès est interdit404: la ressource n’existe pas500: erreur du serveur (voir les logs du serveur)
Vous pouvez visualiser et analyser les requêtes/réponses entre votre client et le serveur avec les outils de développement de votre navigateur (F12, puis onglet Réseau).